
$690 Billion and Nowhere to Plug It In
The AI buildout's biggest risk is the physical world.

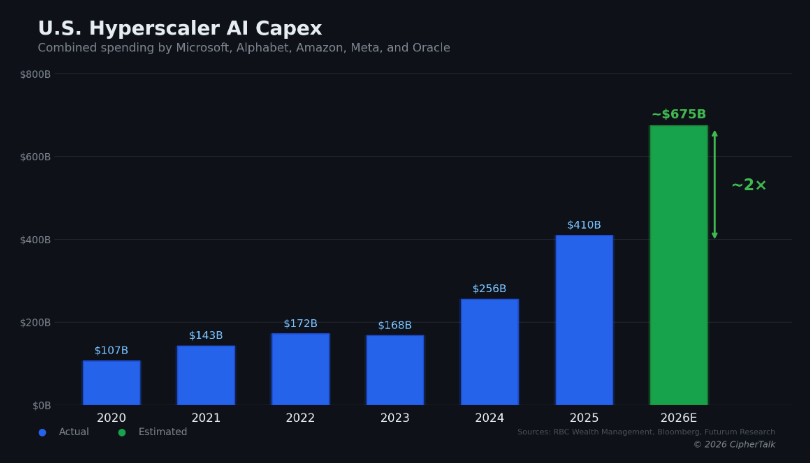
The five largest U.S. cloud and AI infrastructure companies plan to spend between $660 and $690 billion on capital expenditures in 2026, nearly doubling what they spent last year. Amazon committed roughly $200 billion, more than $50 billion above what Wall Street expected. Alphabet guided $175 to $185 billion. Meta set a range of $115 to $135 billion. Microsoft is tracking toward $120 billion or more, and Oracle targets $50 billion, a 136% increase over 2025.
Everyone is talking about the size of the number. Fewer people are asking what happens when that money hits the physical world and the physical world can’t absorb it.
The Deal That Fell Apart
Last September, Nvidia and OpenAI announced a $100 billion partnership to build 10 gigawatts of AI data centers. It was framed as a landmark: the two most important companies in AI, locking arms to build infrastructure at a scale the industry had never attempted. Five months later, no contract has been signed and no money has changed hands. Nvidia CEO Jensen Huang conceded the agreement was “never a commitment.” OpenAI has since struck separate deals with AMD and Broadcom for competing chip architectures. The $100 billion figure that anchored so much of the market’s confidence in AI infrastructure was, it turns out, a letter of intent that both sides were already hedging against.
This matters most for Oracle, which is arguably the most exposed company in the entire AI buildout. Oracle signed a $300 billion five-year cloud contract with OpenAI. It is the primary builder of Stargate data centers. It is sitting on more than $100 billion in debt. And Bloomberg reported in December that several of its data centers for OpenAI have already slipped from 2027 to 2028, citing labor and materials shortages. When the Nvidia-OpenAI deal stalled, Oracle’s stock dropped, and the company posted on X: “We remain highly confident in OpenAI’s ability to raise funds and meet its commitments.” When a company has to publicly reassure the market that its biggest customer can pay, investors notice.
The circular financing question deserves more scrutiny than it is getting. Nvidia invests in OpenAI. OpenAI uses that capital to lease Nvidia chips through Oracle’s data centers. Oracle borrows to build those data centers. If any link in that chain weakens, the exposure cascades. Bank of America noted that hyperscalers are now spending 94% of their operating cash flow on capex, and Meta and Oracle alone issued $75 billion in bonds and loans in the fall of 2025, more than double the annual average over the past decade.
None of this means the demand is fake. AWS grew 24% year over year last quarter, its fastest growth in 13 quarters. Andy Jassy says capacity is monetized as fast as it gets installed. But the financial structure backing the buildout is more fragile than the headline spending numbers suggest, and the fragility is downstream, in the physical world where the money has to become concrete and copper and running machines.
The Five-Month Fantasy
Here is something you will not find in any earnings call or analyst report. People building new data center sites right now cannot get power guarantees two years out, even though the construction itself takes that long. Utilities and grid operators are being asked to commit capacity for facilities that will not be operational for 24 months, and they cannot do it because they do not have the generation, the transmission, or the regulatory approvals lined up on that timeline.
At the same time, the customers commissioning these builds want sites operational in five months.
That gap between what buyers expect and what the physical world can deliver is the most important dynamic in AI infrastructure right now. Microsoft disclosed an $80 billion backlog of Azure orders it cannot fulfill because of power constraints. Meta broke ground last week on a 1-gigawatt campus in Lebanon, Indiana, backed by more than $10 billion. Its planned facility in Louisiana could eventually scale to 5 gigawatts, roughly the output of five nuclear power plants, for a single company. The U.S. grid was largely built between the 1950s and 1970s, and approximately 70% of it is approaching end of life. Companies are exploring small modular reactors, direct utility partnerships, and in some cases buying power plants outright. xAI put a $20 billion data center in Southaven, Mississippi, largely because the power was available there. The geography of AI is being determined by where the electrons are, not where the engineers live.
And even where the electrons exist, the people do not. The U.S. construction industry is short roughly 439,000 skilled workers, with most of the gap in the exact trades data centers need: electricians, pipe fitters, and commissioning technicians. Over 400 data centers are under development across the country. A single campus now requires up to 5,000 workers at peak construction. Wages are up 25 to 30 percent, with electricians earning well over $100,000, and contractors still report project backlogs approaching 11 months. Meanwhile, 23,000 experienced workers retire from the construction industry every year, and there is no pipeline replacing them at the rate this buildout requires.
The companies spending hundreds of billions to automate knowledge work are bottlenecked by the physical trades they have collectively underinvested in for decades.
Who Gets to Build the Future, and on Whose Terms
Then there is the political layer, which adds a dimension most infrastructure analysis ignores.
The Pentagon is threatening to sever its relationship with Anthropic because the company will not allow fully unrestricted military use of its AI model. Claude is the only frontier AI model currently deployed on classified U.S. military networks. OpenAI, Google, and xAI have all agreed to lift their safety guardrails for Pentagon use. Anthropic has not. Defense Secretary Pete Hegseth is reportedly close to designating Anthropic a “supply chain risk,” a label normally reserved for foreign adversaries. An anonymous senior Pentagon official told Axios: “It will be an enormous pain in the ass to disentangle, and we are going to make sure they pay a price for forcing our hand.”
This standoff matters for the infrastructure story because it exposes who is buying all this compute and why. A significant share of the demand driving the buildout is coming from government and defense applications. The Stargate project was announced at the White House with President Trump standing alongside the CEOs. If the political relationship between Washington and the leading AI labs determines which models get deployed on which networks, it also determines which data centers get built, where, and for whom. AI infrastructure is becoming national industrial policy, not a market that sorts itself out through supply and demand alone.
The Last Mile Nobody Talks About
There is one more constraint downstream from all of this that gets almost no attention. Once a data center is built and powered, the hardware inside it still has to be installed, configured, tested, and brought online. Every rack, every server, every GPU cluster requires someone who understands the specific tooling for that vendor’s hardware, that generation of chip, and that particular system configuration.
The pool of embedded systems engineers who can do hardware bring-up at scale is even smaller than the construction workforce. These are the people who connect software to physical machines, who debug firmware, who take a cluster from powered-on to production-ready. There are no bootcamps for this work. The knowledge is hard-won and typically locked inside vendor-specific workflows that break with each new chip generation.
But bring-up is only the beginning. Once a facility is running, the operational challenges compound. Provisioning new hardware into production environments is still a painfully manual process at most organizations, often taking days or weeks per device when it should take minutes. When something fails, and in a facility running tens of thousands of GPUs something is always failing, mean time to recovery determines whether that rack is generating revenue or burning electricity for nothing. Recovery workflows are frequently manual, ad hoc, and dependent on a handful of engineers who happen to know how a particular vendor’s tooling works for that particular chip generation. When the next generation of silicon ships, much of that institutional knowledge becomes obsolete, and teams start over.
This is the part of the AI infrastructure story that almost never makes it into earnings calls or analyst reports. The hyperscalers talk about how many gigawatts they are building. They do not talk about what happens when a firmware update bricks 200 nodes at 2 AM, or when a new GPU architecture arrives and the existing provisioning tools do not support it, or when a field technician at a remote site has to call an engineer in another time zone to walk through a recovery procedure that has never been documented. Uptime at scale is not a software problem or a hardware problem. It is a systems problem that lives at the intersection of both, and the number of people in the world who can solve it is vanishingly small.
The path from “we will spend $200 billion” to “this infrastructure is generating revenue” runs through all of these constraints: grid capacity, construction labor, provisioning speed, recovery automation, and the engineers who keep hardware running once it is deployed. The companies that figure out how to compress the full deployment and operations cycle will capture disproportionate value from this spending wave. Everyone else will be waiting on electricians.
CipherTalk covers AI infrastructure, compute, and the physical systems behind the technology reshaping how we live and work. If this was useful, share it with someone who should be reading it. [Subscribe here] to get these posts in your inbox every week.