

A few headlines this month tell us something important about where enterprise infrastructure is going—and where it’s still stuck.
First, the Cloud Native Computing Foundation promoted an open-source project called OpenYurt to its “incubating” tier. OpenYurt is one of the few serious attempts to help companies run software across all three environments: public cloud, on-prem data centers, and distributed edge devices.
Second, a research group called 360Quadrants published its rankings of companies building orchestration software for edge AI. Three names—Barbara, Gorilla Technology, and Intent HQ—came out on top. They’re not household names, but they’re quietly powering edge deployments in manufacturing, telco, and smart city environments.
And finally, the physical infrastructure is catching up. Verizon announced its next wave of V2X (vehicle-to-everything) deployments using low-latency edge nodes, and Rockwell Automation began rolling out its OptixEdge gateway for running AI models at industrial sites.
These announcements came from very different corners: open source, enterprise AI, telecom, and industrial automation. They're signs that edge deployments are real, and growing fast. But they also expose something more important, the same bottleneck: the tools to manage and orchestrate all of it, especially across cloud, on-prem, and remote nodes, are still limited, fragmented, or missing entirely.
The quit crisis
The core problem with coordination in today’s hybrid environments is fragmentation, both technical and operational. Applications are now distributed across on-prem systems, public clouds, and edge devices. But there’s no shared runtime, no consistent way to manage application state, and no built-in mechanism to reason about multi-node behavior. If one edge node goes down or a network blips, the entire system might fail silently.
This fragility becomes especially dangerous when edge nodes need to act autonomously. Take a smart grid: devices must communicate with each other locally, make quorum-based decisions, and stay in sync with the cloud when available. But today's orchestration tools assume always-on connectivity and stateless nodes. They weren’t built for environments where latency matters, links drop, or regulation forbids cloud round trips. The gap isn’t theoretical. It shows up in every delayed update, every stuck deployment, every rebooted edge gateway that drops offline for hours. Without native coordination—autonomous, multi-node, resilient—edge becomes chaos.
What’s at stake?
Think about your daily experience: traffic lights that respond dynamically to congestion, power systems that maintain stability during blackouts, hospitals analyzing patient vitals in real time, or driver-assist features in your car. Behind those systems are networks of sensors, gateways, and servers with the intelligence to act together. But that coordination isn’t happening reliably. When orchestration fails:
Traffic systems can misalign signal timing, creating delays.
Factories may have unplanned shutdowns, cutting production and jobs.
Healthcare devices may miss alerts or fail to update on-site.
Vehicles may not receive critical updates, leading to safety hazards.
Essentially, orchestration is the invisible software that glues these systems together. Today, it’s a collection of brittle scripts and separate consoles. Not a unified, dependable layer. And when it fails, people notice. Traffic lights go out of sync. Retail systems fail during outages. Hospital monitoring tools miss critical updates. In military or emergency response contexts, that kind of failure becomes a national security problem.
The infra rebound
A short history on where we compute
Over the past two decades, enterprise computing has swung between centralization and decentralization. In the early 2000s, most businesses ran applications on-premise (servers lived in closets or corporate data centers). The cloud changed that. AWS, Azure, and GCP offered cheaper, elastic infrastructure with fewer people and faster deployments. By the mid-2010s, nearly every startup defaulted to the cloud. Even large enterprises began “lifting and shifting” legacy workloads to reduce costs and retire infrastructure. But centralizing compute introduced new costs: latency, egress fees, regulatory complexity, and a dependency on long-haul connectivity that didn’t suit every use case.

As cloud matured, edge computing emerged in response. Instead of routing everything back to cloud, edge pushed compute closer to where data gets created—in factories, vehicles, sensors, and stores. It promised faster response times, lower bandwidth usage, and improved data sovereignty. At the same time, IoT scaled from pilots to production, creating vast amounts of real-time data with physical consequences. That created a new need: distributed coordination. Smart grids, autonomous vehicles, logistics networks, and manufacturing systems now depend on hundreds or thousands of devices making decisions at the edge… often without reliable cloud access. The cloud never went away. But the idea that it could do everything no longer holds.
Meanwhile, a parallel shift has unfolded in how software gets written and run. Traditional applications had predictable logic and centralized control. Today, AI agents operate in more probabilistic, distributed ways. Workflows involve model inference, continuous learning, and coordination across environments. Generative models, LLMs, and real-time analytics often need to run locally to meet speed or privacy constraints. A warehouse robot can’t wait for a cloud round trip. Nor can a hospital imaging system. These workloads don’t fit into the original cloud playbook, and they’ve arrived before orchestration systems caught up.
The result is fragmentation. Some workloads stay in the cloud. Others run on-prem for compliance. More and more now deploy to the edge. What we’re seeing now isn’t another swing in the pendulum, but a convergence. Cloud, edge, on-prem, and AI are no longer separate domains, but part of one continuous stack.
What most companies are doing today
Despite years of investment, most edge–cloud–on-prem orchestration still runs on patched-together scripts. Terraform handles provisioning. Ansible handles updates. Prometheus tracks telemetry. Vendor agents control hardware. Thousands of lines of YAML glue it all together.
It doesn’t scale. Enterprises juggle multiple tools and dashboards. There’s no unified view of what's running where. A small site failure can bring down an entire region. And basic tasks like updating firmware still require physical USB keys.
The financial cost is high. According to research published by the IEEE this year, large enterprises now spend €20 to €40 million per year on unplanned integration work just to keep hybrid environments operational. Only 25% of hybrid cloud projects achieve their projected return on investment.
That’s the context behind this month’s announcements. Hardware is being deployed at scale. Orchestration is still the bottleneck.
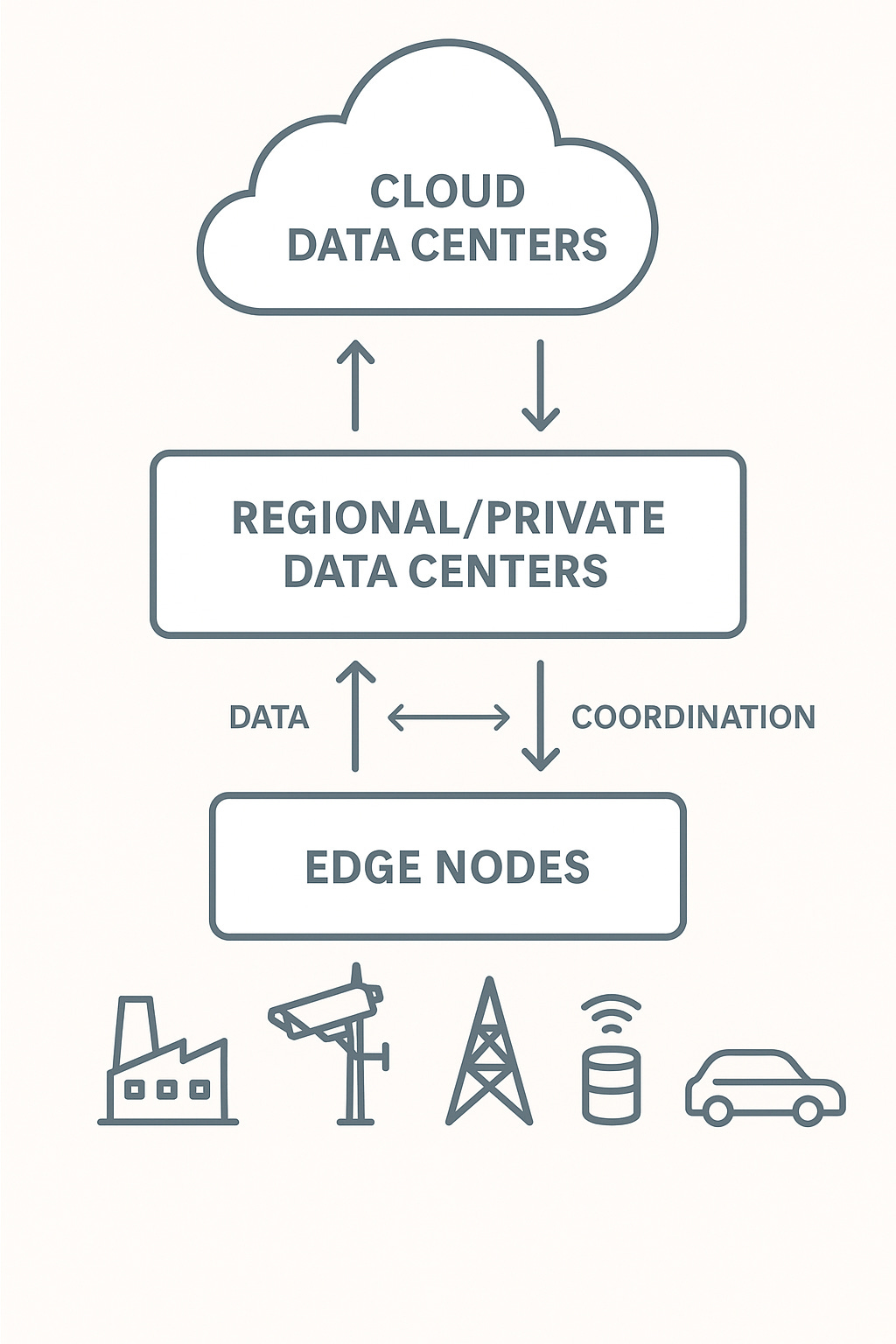
Where current vendors fall short
Cloud vendors like AWS, Azure, and Google pitch tools like Outposts, Arc, and Anthos as hybrid solutions. In reality, they assume stable networks, tie you to their ecosystem, and don’t handle offline coordination well.
Open source projects like KubeEdge and OpenYurt are more flexible. But adoption has been limited outside of China. Support is minimal. And features like mesh-wide coordination or state reconciliation still don’t work reliably in production.
Startups like ZEDEDA (Series C) and Avassa are improving the situation. ZEDEDA focuses on lifecycle and device management in industrial environments. Avassa emphasizes a better developer experience. But none of these tools offer a truly unified way to deploy, monitor, and recover applications across dozens or hundreds of edge sites in real time.
Geopolitics of the edge
Edge infrastructure shifts data processing away from centralized clouds and toward the physical sites where data gets generated—factories, hospitals, vehicles, city systems. This change reduces latency and improves control, but it also raises new questions: who manages the software? where does data go? who has visibility?
Europe has moved first to assert control. Under GDPR, companies must keep personal data within specific jurisdictions. The proposed AI Act adds enforcement around algorithmic use and auditability. European cloud efforts like Gaia-X and France’s “Cloud de Confiance” aim to support this with infrastructure that avoids foreign dependencies. Orchestration tools that rely on U.S.-based control planes or opaque APIs fall short of those requirements.
China has locked its edge systems within national borders. The 2021 Data Security Law mandates onshore storage and processing for critical data. Chinese vendors now deploy closed-loop orchestration that runs entirely without outside involvement, especially in sectors tied to telecom and defense.
The U.S. treats edge security as both a commercial and strategic priority, though efforts remain fragmented. Defense programs like JADC2 focus on resilient coordination across military domains. Outside that scope, edge deployments often rely on public cloud infrastructure, third-party networks, or vendor-managed gateways. Policies like CMMC and Executive Order 14028 offer security guidelines, but enforcement remains uneven.
Recent attacks show what’s at risk. In 2023, hackers accessed U.S. water treatment systems through vulnerable IoT gateways. That same year, a NATO cybersecurity audit found more than 200 edge devices in European critical infrastructure running without central coordination or logging.
Every country now faces the same question: how to coordinate what runs at the edge. Without a secure, local-first orchestration layer, systems remain opaque and vulnerable. Visibility breaks down. Policy cannot be enforced. In high-stakes environments, control follows coordination. No orchestration, no leverage.
Where we go from here
What’s emerging now is a clear shift toward convergence. Edge, cloud, and on-prem are no longer separate strategies—they’re part of the same operational stack. And with AI workloads pushing real-time, location-specific demands, companies can’t afford brittle, one-directional infrastructure anymore. The orchestration layer needs to evolve into something more intelligent, modular, and responsive: able to coordinate thousands of distributed endpoints while adapting to outages, changing policies, and variable latency. A new generation of companies—some open source, some commercial—are racing to define that layer. But the space remains wide open.
At the same time, the pain points are getting worse. As more devices come online and workloads become more dynamic, the cost of fragmentation rises. Security risks multiply when no one has a full picture of what’s deployed where. Operators burn resources trying to stitch systems together. And the foundational promise of edge computing—resilience, speed, sovereignty—gets undermined when the control plane is scattered or misaligned. The technical challenge is massive, but the coordination problem may be even bigger. The tools to manage this shift are behind the curve, and geopolitical pressures only make the gaps more visible.
So what does real progress look like here? What would it take to build an orchestration layer that’s trustworthy, neutral, and intelligent enough to span cloud, edge, and on-prem—while meeting the regulatory, performance, and security constraints of each?
I’d love to hear from readers across industries: How are you solving these problems today? What have you tried, and where have you gotten stuck?