
Sovereign Compute
How a small number of buildings in three countries became the substrate of cognition, what agency over that question actually looks like, and why Madison would have recognized the fight.

I spent the years before starting Cosmic close enough to the defense and national security side of technology to watch what dependency looks like when it sets in. You watch critical systems be built on someone else’s stack, you watch the imbalance compound silently for a decade, and you watch the moment of reckoning when the dependency gets called in. By then the choices are bad. The only good decisions were the ones made years earlier, when the dependency was still optional and nobody was paying attention.
Sovereign compute is the same shape of problem with the timeline already collapsed. The frontier of machine intelligence, in the literal sense of the most capable systems for reasoning and prediction this species has ever built, now lives in a small number of buildings in California, Texas, and increasingly Abu Dhabi. The people running those buildings are friendly to me. They might not be friendly in ten years. Every layer of the stack underneath those models, the silicon, the optical interconnects, the data centers, the orchestration software, the training data pipelines, the model weights themselves, is concentrated in roughly the same set of hands. The question of who gets to think at the frontier has already been answered for a while. The question of whether anyone else retains agency over that answer is the entire fight.
Sovereign compute is not primarily about data residency (although data residency matters), nor about language and culture (although both matter). Underneath all the policy noise sits a question of whether a country, an institution, or a person retains agency over the intelligence that increasingly runs their world, or hands it over to a small number of foreign firms in exchange for convenience and speed. Those that have figured this out are moving fast. Those that have not are about to discover what dependency feels like at the layer of the stack that decides what their citizens are allowed to know.
How we got here
Sovereign compute has three distinct origin stories that have only recently merged into one conversation, and confusing them is how most of the press coverage gets the argument wrong.
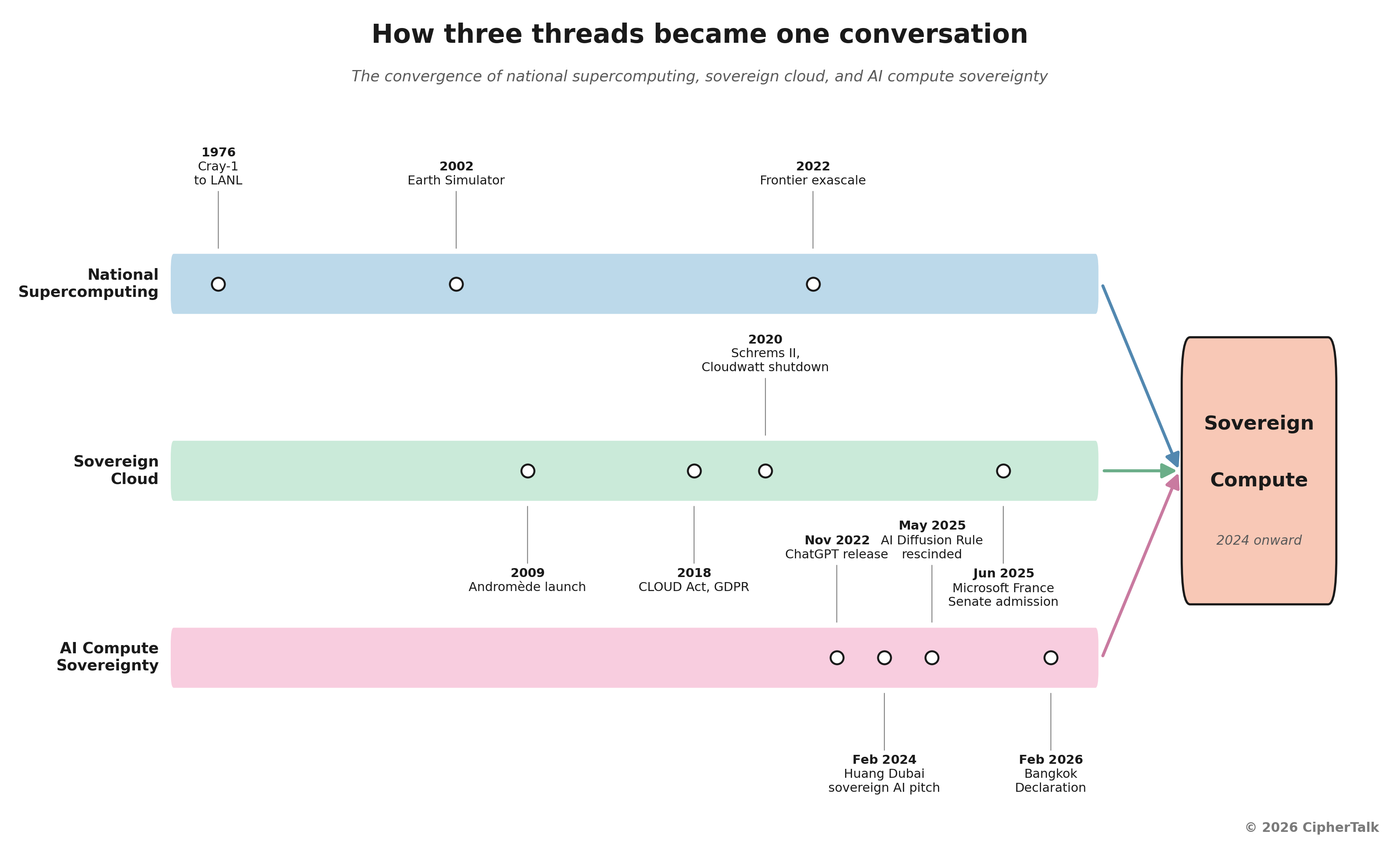
The first origin story is national supercomputing as a Cold War instrument. The earliest case for a government owning its own most powerful computer had nothing to do with culture or residency. The Cray-1 went to Los Alamos in 1976 to simulate nuclear yield. The Soviets built BESM machines for the same reason. Computing capability at scale was a strategic asset from the moment it became technically possible, and the institutions running the largest machines, including Los Alamos, Oak Ridge, NCAR, the UK Met Office, and RIKEN, have carried that lineage straight into the present. When ORNL or LANL or NERSC discusses a sovereign system today, the institution is pulling on a thread that runs back through Eisenhower’s massive retaliation doctrine.
The second origin story is sovereign cloud, which began roughly a decade ago and was a fight about data, not about compute. It crystallized after the 2018 CLOUD Act and the 2020 Schrems II decision. American hyperscalers had built their European businesses on the premise that data physically located in Frankfurt or Dublin or Paris was under European law. The CLOUD Act made that a polite fiction. American law enforcement can compel American companies to produce data stored anywhere in the world, regardless of where the bits sit. The watershed moment for that entire debate came in June 2025, when Microsoft France confirmed under oath at a French Senate hearing that it cannot guarantee data sovereignty against US authorities, even for data stored in France under a French-marketed sovereign offering. The polite fiction died on the record.
The third origin story is the post-ChatGPT realization that frontier AI is a strategic capability concentrated in roughly five firms across two jurisdictions. Epoch AI’s data puts the United States at the majority of global GPU cluster performance, China second, and the rest of the world holding small fractions individually. If you are a serious country and those numbers cross the desk of your defense minister, you do something about it. Jensen Huang crystallized the political pitch at the World Government Summit in Dubai in February 2024: every country needs to own the production of its own intelligence; you cannot allow that to be done by other people. Two years later, the Bangkok Declaration of February 2026, signed by more than a hundred countries, formalized AI sovereignty as a shared policy objective across most of the world.
The logical argument
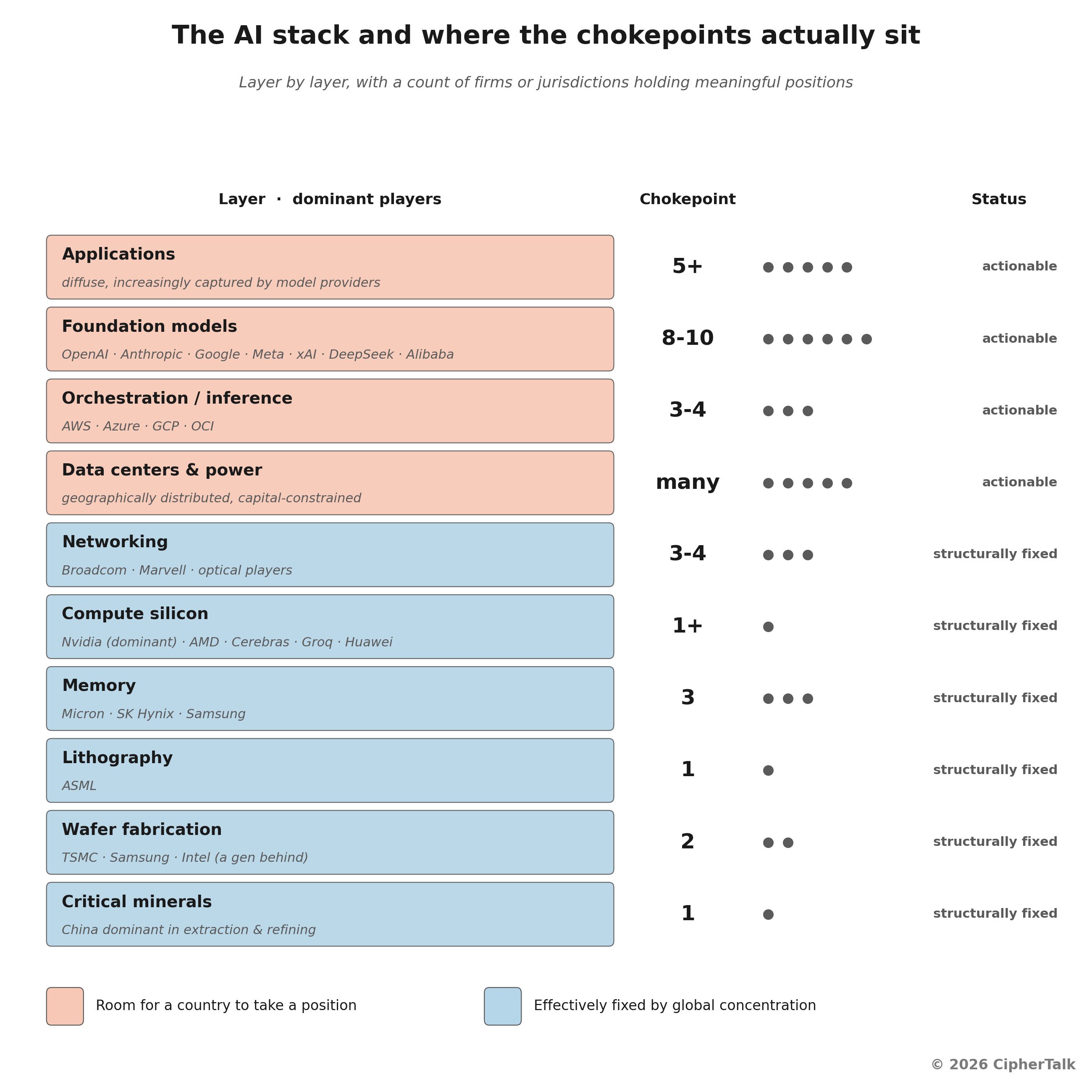
The clean version of the logical argument is that the AI stack has eight or nine layers, every layer has chokepoints, and no country in the world holds all of them. So the policy question is not whether you achieve “full sovereignty,” because no one will, including the United States. The question is which layers you hold yourself, which layers you partner on, and which layers you tolerate dependency for.
At the bottom sit critical minerals (gallium, germanium, neon, rare earths) where China holds dominant positions in extraction and refining. Wafer fabrication is held by TSMC at the frontier, with Samsung and Intel a generation behind. Lithography sits at a single point of failure called ASML. Memory is split between Micron, SK Hynix, and Samsung. Compute silicon is dominated by Nvidia, with AMD, Cerebras, Groq, Tenstorrent, and Huawei Ascend holding most of the rest. Networking is concentrated in Broadcom, Marvell, and a small set of optical players. Data centers and the energy underneath them turn out to be surprisingly hard to scale. Orchestration and inference serving are dominated by a small set of US clouds. Foundation models at the frontier come from roughly five US labs (OpenAI, Anthropic, Google, Meta, xAI) and a handful of Chinese counterparts (DeepSeek, Alibaba, Moonshot). Applications are the most diffuse layer, increasingly captured by the model providers themselves.
Full-stack AI sovereignty is infeasible for almost any country because AI is a transnational stack with concentrated choke points. The implication people draw from that, which is that sovereignty talk is therefore unserious, is wrong. Industry standard, it seems, is what some call managed interdependence: pick the layers where you have genuine comparative advantage, build there, partner for the rest, and use the building to give yourself negotiating power on the things you cannot build. The globalization argument. Vish Nandlall’s June 2026 analysis calls this the bottleneck blueprint: successful national strategies converge on controlling specific bottlenecks, not on owning everything.
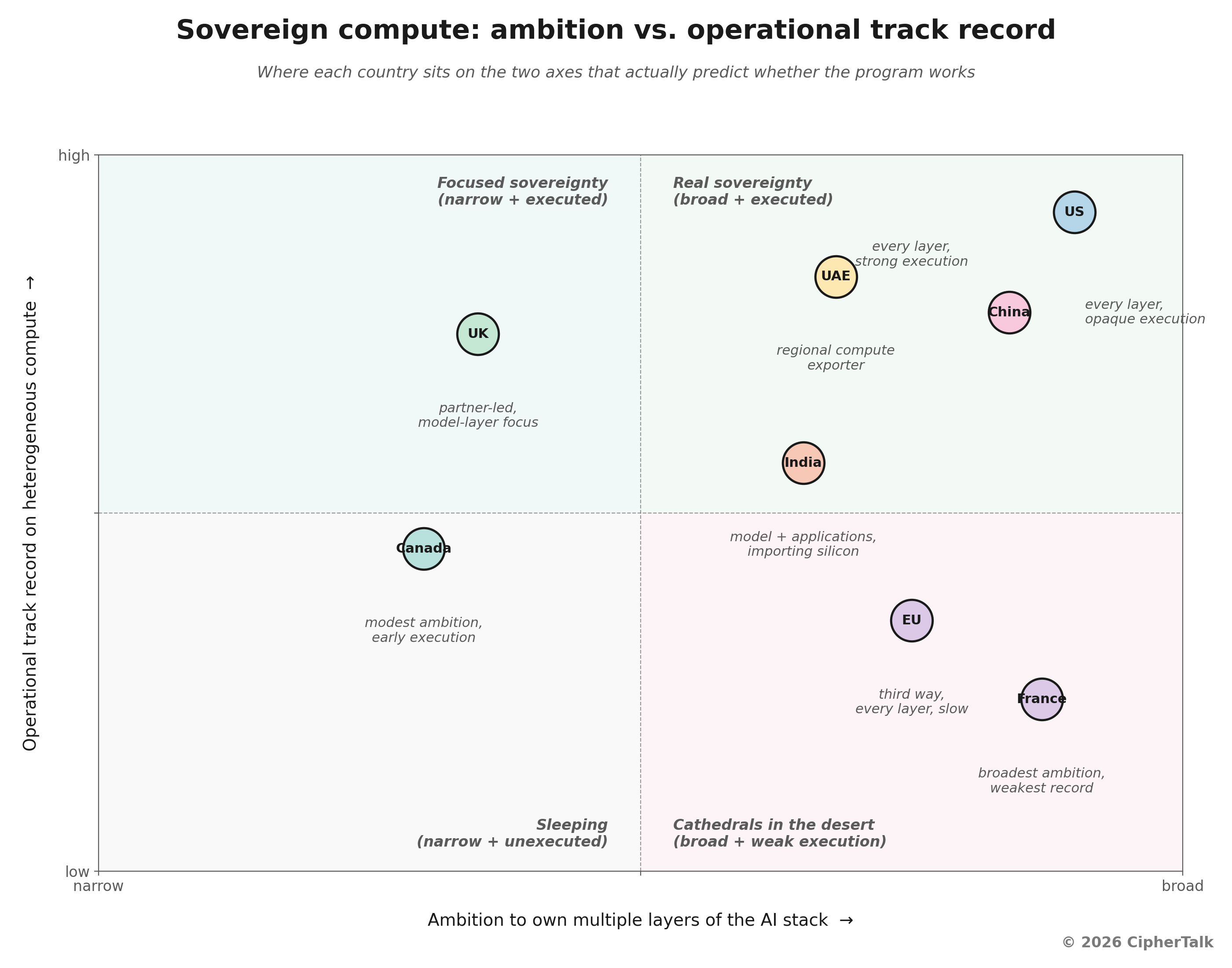
The United Kingdom is the clearest version of this approach. The UK has not tried to construct an indigenous Nvidia or a domestic foundation model lab. It has built Isambard-AI on Grace Hopper silicon, stood up a Sovereign AI Unit in April that operates as a £500 million state-backed venture fund, and partnered openly with Anthropic and Nvidia on the layers where domestic capability is not viable. The UK has taken explicit positions on the model layer, the deployment layer, and the talent layer, and is being honest about importing the rest.
The opposite extreme is France. The French state launched Project Andromède in 2009 with €150 million of state money to build a sovereign cloud, split into two competing entities (Cloudwatt and Numergy) that posted combined revenue of €8 million against billion-euro business plans before being quietly shut down by 2020. Macron’s €109 billion AI Action Summit number in February last year included roughly a third to nearly half from a single Abu Dhabi sovereign wealth fund with no legal obligation to deliver. Mistral is the real asset France has, and in early 2026 Mistral raised €830 million in debt from BNP Paribas, Crédit Agricole, HSBC, and MUFG to buy roughly 13,800 Nvidia chips for a Paris data center, on top of the 18,000 Grace Blackwell systems already underwriting Mistral Compute. Mistral is also closing what started as Apache 2.0 open weights, with its most capable systems now behind commercial licenses and sovereignty contracts. The lesson there is not that France should give up on sovereignty, but that sovereignty everywhere produces a worse outcome than sovereignty in the layers where a country can actually win.
The economic argument
The economic case for sovereign compute is more boring and more important than the policy version makes it sound. It is fundamentally about value capture. AI is going to be a meaningful fraction of GDP growth this decade in every economy where it is allowed to run, and the economic value generated by AI gets divided between
the firms running the models,
the firms providing the compute,
the firms providing the silicon, and
the customers using the output.
If your country sits on the customer side of that ledger at every layer, you’re facing inbalance payments problem that compounds over time.
The simplest version of the math: an enterprise customer in Germany spending €100 million a year on inference today is sending most of that money to American clouds, who pass a substantial percent on to Nvidia and TSMC. A sovereign alternative captures some of that spend domestically, generates tax revenue, creates engineering jobs, and accumulates operational expertise that compounds. Even a partial sovereign stack, owning the inference layer on top of imported silicon, retains a real share of the value chain instead of routing it offshore.
This is also where the critique lands hardest, because most sovereign compute programs do not actually capture value, they spend it. The EU AI Gigafactories program will deploy roughly €20 billion in public and private capital across four to five facilities, each with about 100,000 advanced processors, on top of the 19 AI Factories EuroHPC already has operational or selected. Each gigafactory is a multi-billion-euro capital project. The unit economics question that determines whether the program works is whether those facilities run at hyperscaler-class utilization rates, above 70 percent, with paying enterprise workloads. If they end up running at 30 percent utilization with grant-funded academic experiments, the program produces what one analyst called cathedrals in the desert: beautiful infrastructure that does not generate the cash flows to justify itself. A GPU farm does not spontaneously generate a thriving AI platform, a publicly funded supercomputer does not automatically birth a hypergrowth startup, and a sovereign label on a data center does nothing to erase underlying dependence on Nvidia hardware, American software orchestration, and US cloud distribution channels. Utilization quality matters more than nameplate FLOPS, and most of the public European numbers conflate the two.
The Gulf model is the most economically interesting because it is the most explicit about value capture. The UAE and Saudi Arabia are not pretending to build a domestic Nvidia. They are buying the silicon at scale, building the data centers at scale, and positioning themselves as regional compute exporters into a 2000-mile radius that covers Africa, South Asia, and parts of Europe. Stargate UAE is a 1-gigawatt cluster inside a 5-gigawatt campus, operated by G42 in partnership with OpenAI, Oracle, Nvidia, SoftBank, and Cisco, with the first 200-megawatt phase coming online in 2026. G42 and HUMAIN each received Commerce Department approval in November 2025 to import compute equivalent to 35,000 GB300 systems each, the highest-end chip Nvidia makes. The trade was straightforward: deep security commitments and supply chain assurances in exchange for chip access. That is not sovereignty in the maximalist sense. It is value capture at the infrastructure layer, paid for with security alignment.
The United States is doing the same thing in reverse. After the Trump administration rescinded the Biden-era AI Diffusion Rule in May 2025, the replacement approach has been country-by-country negotiation, where chip access is the carrot and the implicit threat is loss of access to the American AI stack altogether.
India sits in a third bucket. The IndiaAI Mission has deployed more than 38,000 GPUs against an original target of 10,000, built a national compute portal that subsidizes access for startups and researchers, and selected Sarvam to build a domestic 120-billion-parameter open-source foundation model. The economic bet is on the model and applications layers, on top of imported compute, with the longer game on indigenous silicon still in front of them. Canada closed applications on its AI Sovereign Compute Infrastructure Program on June 1, 2026. Across the US, Europe, the Gulf, and Asia, announced sovereign compute commitments now approach a trillion dollars in headline figures, though much of that total is buildout intention rather than funded spend.
The philosophical and emotional argument
The emotional case is the one nobody writes about clearly, because it sounds soft next to economics and policy. It is also the part that explains why this issue moves so fast in capitals once leadership actually thinks about it, and the part that connects sovereign compute to the deepest commitments of the American constitutional project.
Federalist No. 10, written by Madison in November 1787, was an argument against the concentration of power, even when that power is held by competent and well-intentioned people. The whole American constitutional architecture rests on that bet. The Founders distributed power between branches, between federal and state, between government and the press, and between citizens and any concentrated interest, on the theory that diffusion produces better outcomes than centralization even when the centralization is benevolent. Madison’s specific worry was factions, his term for any organized interest that could capture the levers of government and turn them against the rest of the country. His architectural answer was that a sufficiently large and federated republic would make any single faction structurally unable to dominate. Concentrated power was the danger, in any direction, foreign or domestic.
Mill made a parallel argument about freedom of thought specifically. On Liberty holds that thought concentrated in any single source, however reasonable that source might be, narrows what is knowable. The right to seek and receive information from a plurality of sources is the precondition for the exercise of any other freedom. You cannot vote intelligently, contract intelligently, or live intelligently if a single institution decides what arguments you ever hear.
Foreign-controlled AI sits in tension with both of those traditions in a way that should be obvious to anyone who takes them seriously. Intelligence is not a neutral commodity. Intelligence shapes what questions get asked, what answers are visible, what arguments are considered legitimate, and what frames the people who use it come to think in. A foundation model trained primarily on English internet text, fine-tuned by a small group of American engineers, and deployed through interfaces optimized for American users does not produce neutral output. It produces output that reflects the assumptions of the people who built it. Those assumptions might be reasonable, charitable, even broadly correct. They are still not the assumptions of every country whose citizens are now using the model to write their essays, debug their code, summarize their meetings, draft their laws, and plan their lives.
Self-determinism is claimed by libertarians, though I think they have been slower to make this particular argument publicly. The libertarian intuition has always been that concentrated infrastructure is a single point of capture, regardless of who holds it. The fact that the holders are private firms rather than governments does not change the analysis. If three or five companies decide what eight billion people can ask, learn, and reason about, that is the most concentrated cognitive infrastructure in human history. The First Amendment tradition is going to have to extend in some form to the upstream layer where ideas get shaped before they are spoken, and serious work on that question has already begun at the Knight Institute and in the Stanford Federalist Society’s 2026 symposium, which explicitly framed foreign-built models as a risk to American freedom. A FIRE poll from January 2026 captured the consumer-side instinct accurately: Americans overwhelmingly want free speech protected in AI regulation, with 72 percent concerned about AI laws being used to suppress political criticism. The same instinct, generalized to the production of intelligence itself, is what sovereign compute is responding to in every country that takes it seriously.
The visceral reaction in Paris and New Delhi and Riyadh is the same visceral reaction countries have always had to dependency on foreign infrastructure. Countries have always treated certain capabilities as too important to outsource: currency, military, the institutions that shape what their children learn. Outsourcing the substrate of intelligence, to a small number of firms in a foreign country, feels wrong on a register that has nothing to do with cost-benefit analysis. The reason Macron’s “third way” rhetoric resonates in Europe is not that anyone has done the math on European AI ROI; it is that a continent watching itself become a customer of a technology it once expected to invent is having a reaction that registers below the level of policy. The reaction is pro-agency, not anti-American, in most cases. Countries do not want to discover, ten years from now, that the most important strategic capability of the century is rented from someone else. And inside the United States, the same logic could apply in reverse. A small number of American firms controlling the substrate of cognition for the entire planet is a Federalist 10 problem with the polarity flipped. Anyone who takes the original American constitutional project seriously should think deeply about the current concentration, regardless of which flag flies over the data center.
There is a personal version of this too, and I think people in my line of work feel it more than they say. I work on the layer of infrastructure that sits below the models, because the models themselves are increasingly outside the reach of any company that did not start that race in 2018. The compute, the operations, the reliability of new systems, the way fleets of heterogeneous silicon actually run in production, those are the layers where smaller firms can still take meaningful positions. Building there is, for me, a way of holding agency over a future that would otherwise be determined elsewhere. That is the same instinct that drew me to technology in the first place.
If you do not feel some version of that pull, sovereign compute will read as a policy abstraction. If you do feel it, you already know what this piece is about.
TL;DR
My honest guess is that sovereign compute as a category is going to produce a small number of national programs that genuinely move the needle, a larger number of programs that mostly subsidize national champions whose product nobody wants, and a much larger number of expensive data centers that run at thirty percent utilization while the press releases age. The CNAS Sovereign AI Index from April 2026 already shows the divergence opening up between countries with infrastructure that actually runs production workloads and countries with press releases. The countries that do this well will share three properties: realistic assessment of which layers of the stack they can actually own, willingness to import the rest without pretending otherwise, and operational competence at running heterogeneous infrastructure across vendors and generations of silicon.
That last property is, in my experience, the one most often underestimated. Rack-and-cabling a thousand-node cluster is mostly procurement. Keeping it running at production utilization across multiple GPU generations, multiple vendors, multiple firmware revisions, and the inevitable silent-data-corruption events that show up at scale is operations work that almost nobody in the sovereign compute conversation talks about. We work with national labs, neoclouds, and defense folks whose fleets look exactly like the fleets that every sovereign compute program is about to inherit, and whose operational problems are exactly the problems those programs will discover on day one of going live.
That is the boring version of what owning the intelligence stack looks like. The work is operational competence in the layers nobody puts on a slide: bring-up, firmware, telemetry, the substrate beneath the model. Teams that build that competence end up with compute that runs. Everyone else ends up with subsidized cathedrals and infrastructure that belongs to someone else.
This is the clearest articulation of the managed-interdependence frame I've read, and the operational-competence point at the end is the one I keep waiting for people to make. The gap between rack-and-cabling a cluster and keeping it at production utilization across firmware revisions and silent-data-corruption events is exactly where the press releases stop and the actual work begins.
The layer I'd add sits just above the substrate you describe: trust. Once a country imports silicon, partners on orchestration, and runs heterogeneous fleets across vendors and generations, it inherits a verification problem it can't see. Which model actually ran? Were the weights the weights that were promised, or a quieter, cheaper substitute? Did the computation happen as specified? Centralized providers answer this by reputation — you trust the brand. A sovereign program stitched together from imported layers has no brand to trust; it has a supply chain it didn't fully build.
That's the part I work on — content-addressed model identity and execution attestation, so a verifier can confirm what ran without trusting the operator. It's the same Federalist 10 instinct applied one layer up: diffusion of capability only produces agency if you can audit the diffused parts. Otherwise sovereignty is a label on a data center, which is the failure mode you name precisely.
The operational competence you describe and the verifiability I'm describing are the same bet from two angles: the systems that survive are the ones where the substrate actually runs and can prove what it did.
Great post Meg! I'm not sure how sold I am on "AI sovereignty" as the complexity and interconnectedness of the tech supply chain makes it really hard - that's not to say countries should be discouraged from trying. On the model and application layers, this is very possible but less so within areas like semis, power, hardware and infrastructure. In my view, it looks quite fragmented.