


The Broken Economics of AI
Why Cloud Computing Can't Scale Intelligence Forever

For centuries, technology has been the greatest lever of agency. The printing press unlocked knowledge. The industrial revolution unlocked production. And the internet unlocked access. The web wasn't built to be centralized. The very design was resilient—packets moving across any available path, built to withstand outages and failures. That architecture democratized information, gave people tools, and put power into billions of hands.
Artificial intelligence is being sold to us as the next internet. But AI isn't following the same ethos. Instead of being distributed, intelligence is concentrated in a few companies who own the models and the compute. Instead of costs falling with scale, demand is rising faster than hardware improvements can keep up. Running large models can cost up to twenty times more than the price you see at the surface. And those who feel the weight first are the ones furthest from centralized infrastructure—the people without control of the compute.
We already see this in places where cloud backhaul can't be assumed: disaster zones, remote operations, and battlefields. But the way AI is scaling, fragility won't stay confined there. The broken economics will touch everyday businesses and nations that discover their agency is limited by infrastructure they don't own.
The economics work like Russian dolls of subsidy. Microsoft loses money on every GPT-5 call to capture Office and Azure customers. OpenAI loses money on API pricing to gain developer mindshare. Cursor loses money on unlimited plans to hook coding teams. Each layer absorbs losses, betting they can change terms later.

The Meter That Lies
A token in a large language model works like a tiny meter reading. One request flows through a model and a meter ticks for every small chunk of text processed and produced. Providers sell access to that meter. Developers and consumers pay per million ticks. That frame helps a normal reader see where money changes hands and where stress concentrates in the whole system.
OpenAI's recent GPT-5 release makes this concrete. Pricing for the main GPT-5 model sits at $1.25 per million input tokens and $10 per million output tokens. Anthropic's Claude 3.7 Sonnet charges three dollars per million input tokens and fifteen dollars per million output tokens. These numbers look reasonable. Cheap, even.
But here's the smoke screen: those prices bear little relationship to what compute actually costs. Consider the math behind a single H100 GPU renting for around $2 per hour from smaller cloud providers. Running an efficient model can generate hundreds of tokens per second on that hardware. But frontier models with deeper reasoning and long context are heavier, and throughput can drop significantly compared to smaller models—meaning the same GPU that produces millions of cheap tokens in simple tasks delivers far fewer when handling complex reasoning chains.
The real cost to OpenAI for generating those ten-dollar-per-million output tokens? Likely anywhere from $50-$200 per million tokens when you factor in H100 rental rates, memory requirements, power consumption, and the hidden "thinking tokens" that reasoning models generate internally. The math gets worse with every layer of reasoning, every expansion of context, every increase in model sophistication.
That twenty-to-one cost differential reveals the truth behind AI pricing: these companies are lighting money on fire to build market share. The meter shows you a tiny number while billion-dollar compute bills accumulate behind the scenes.
The Great Subsidy
The economics work like Russian dolls of subsidy. Microsoft loses money on every GPT-5 call to capture Office and Azure customers. OpenAI loses money on API pricing to gain developer mindshare. Cursor loses money on unlimited plans to hook coding teams. Each layer absorbs losses, betting they can change terms later.
The end user sees none of this. A developer pays twenty dollars monthly for "unlimited" AI assistance. Behind that interface sits a chain of companies each burning cash: Cursor forwards hundreds in API costs to OpenAI, which forwards thousands to Microsoft Azure, which amortizes tens of thousands in H100 hardware costs across millions of requests hoping volume will eventually justify the math.
This subsidy dilution creates dangerous disconnection from reality. Users develop workflows assuming AI will stay cheap. Startups build business models on artificially low inference costs. Enterprises plan digital transformations based on pricing that reflects venture capital and hyperscaler subsidies, not sustainable unit economics.
The subsidy chains grew so deep that most people using AI today have no idea what compute actually costs. A coding session that feels free might burn through fifty dollars of real hardware costs. A lengthy document analysis that costs two dollars in credits might consume two hundred dollars worth of GPU time. The gap persists only because multiple companies in the stack are choosing to lose money.

History shows what happens when subsidy chains break. Uber burned billions subsidizing rides to build habits, then raised prices when growth slowed. Amazon Web Services ran at razor margins to dominate cloud infrastructure, then increased rates once competitors fell behind. WeWork subsidized office space until investor patience ended and reality hit.
AI follows the same playbook, but with higher stakes. When the subsidies end—through investor pressure, regulatory changes, or simple financial exhaustion—prices won't rise gradually. They will snap back toward true costs overnight.
Consider the cascading effect: OpenAI raises API prices to match compute costs. Cursor's unlimited plans become impossible economics and shift to strict usage caps. Coding assistants that teams depend on suddenly carry enterprise software pricing. Workflows that once felt magical become expensive line items that CFOs question.
The fragility runs deeper because AI consumption is habitual and hard to optimize quickly. Unlike cloud storage where teams can archive old files, or compute where they can optimize code, AI usage patterns resist easy reduction. Once a team builds workflows around intelligent assistance, stepping back feels like moving from electricity to candles.
The Math Isn’t Mathing
Two forces pull in opposite directions. On one side, providers slash per-token prices. Headlines celebrate a 280-fold drop in costs for GPT-3.5 level performance over eighteen months. That narrative shaped expectations for an entire industry and convinced everyone that AI would follow the same cost curve as previous technologies.
On the other side, real-world supply for compute and power stays impossibly tight. Nvidia H100 units still command mid-five-figure prices for direct purchase—around $25,000 to $40,000 per chip—and multiple dollars per hour to rent. Those numbers come before networking, storage, memory, land, and people.
The gap between what providers charge and what compute actually costs reveals the truth: AI is being subsidized. The hyperscalers are eating massive losses to build market share and lock in customers. But subsidies always end.
The Physics of Constraint
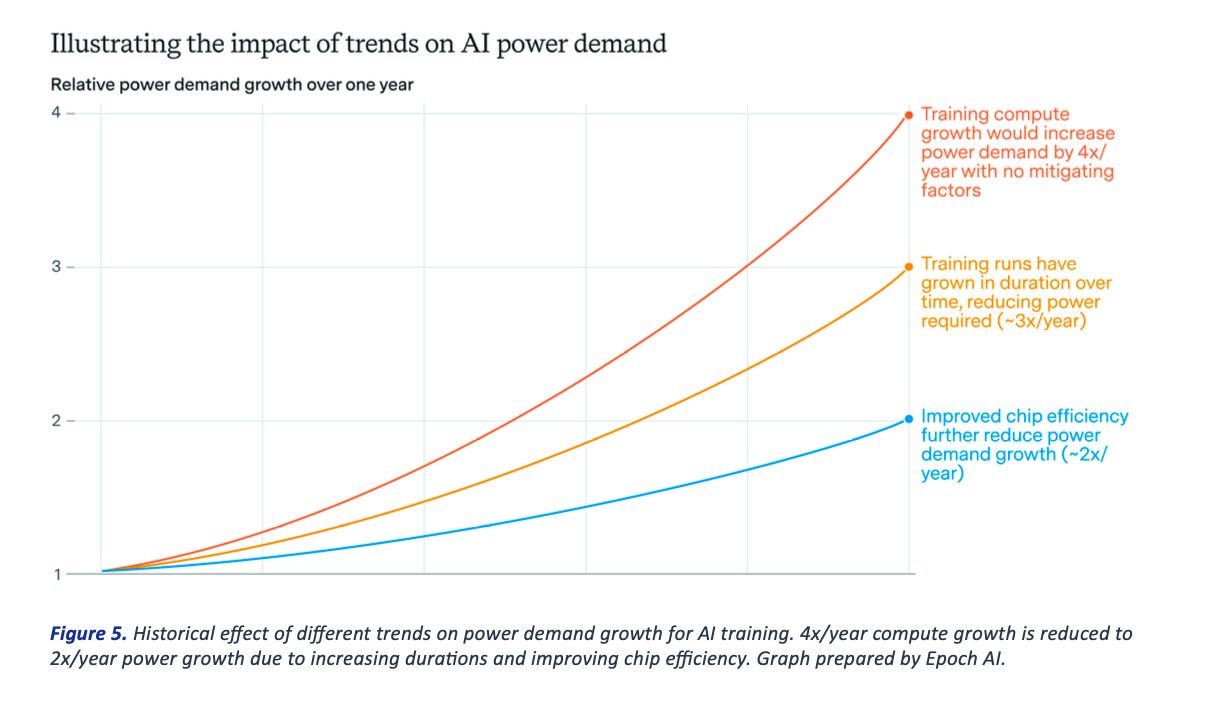
Wait times have not vanished. Industry trackers through spring and summer flagged multi-month queues for H100 deliveries and backlog risk for upgrades. Even when a team secures chips, a modern facility takes time. Power constraints are pushing new construction timelines into 2027 and beyond in primary markets, with record pre-leasing to lock scarce megawatts. Build cycles run three to six years from land through construction when greenfield power and permits enter the picture.
Energy demand compounds the squeeze. Global data center electricity use is projected to roughly double to around 945 terawatt hours by 2030, with AI-optimized sites driving a large share of growth. That doubles within a few years while transmission infrastructure takes six years to build. The math doesn't work.
Consider xAI’s Colossus Memphis as the rare exception. xAI repurposed a former Electrolux plant and stood up an incredibly large data center, nicknamed Colossus, at remarkable speed, relying on temporary on-site generation that drew local scrutiny. The project moved quickly because the hard parts—an industrial shell and existing utility hookups—were already in place. That kind of rapid redeployment is the anomaly. Most sites don’t come with ready-made infrastructure, which is why scaling new capacity usually drags, even as demand accelerates.
The Stack That Doesn't Add Up
A simple plan can go sideways under today's economics. A team charges a customer one dollar for a feature. That feature triggers five dollars of AI calls. A foundation model partner forwards seven dollars to a hyperscale host. A chip maker sells parts at a price that maps to thirteen dollars against that same feature if a buyer amortizes hardware. That stack leaves negative margins for the application layer.
Two examples make the pressure real:
The Coding Assistant: A tool that leans on high reasoning and long context burns output tokens and adds thinking tokens. GPT-5 charges ten dollars per million output tokens and counts internal reasoning in that bucket. Claude 3.7 counts extended thinking the same way at fifteen dollars per million. A heavy user can eat through monthly credits in days. Hence the clampdowns across services.
The Context Window: A chat widens context to hundreds of thousands of tokens. OpenAI markets massive context windows for GPT-5. Anthropic offers 200,000 tokens for Sonnet 3.7. Feeding giant contexts pushes memory pressure onto GPUs and reduces throughput. Providers must raise rates, route to smaller models, or cap usage.
The Whales That Break the Model
A single user ran $35,000 worth of inference in one month under a flat $200 subscription fee on an Anthropic service. That kind of behavior breaks any flat subscription model for startups that resell someone else's API. Providers responded with new rate controls and account enforcement.
This reveals the fragility of the current pricing model. When someone actually uses AI at scale for real work, the economics collapse. The system works only as long as most users stay light.
The Coming Reckoning
My prediction? The broken economics create three inevitable outcomes:
Pricing Will Rise: As subsidies end and true costs surface, AI services will become expensive. The current race to the bottom on simple tasks will continue, but complex reasoning and giant contexts will carry premium prices that reflect real compute costs.
Access Will Fragment: Not everyone will have equal access to AI capabilities. Distance from data centers, local power grids, and geopolitical boundaries will determine who gets intelligence and who doesn't. We're already seeing this in regions with poor internet infrastructure.
Agency Will Concentrate: The companies that own the compute will own the decisions. Applications built on someone else's infrastructure will face sudden limits, pricing changes, and service interruptions they can't control.
The alternative path?
Supply will expand, yet constraints will persist. The path to 945 terawatt hours by 2030 reflects a structural shift, not a temporary shortage. Record construction still warns of power availability issues into 2027 and beyond.
In my opinion, the solution isn't more cloud computing. It is more efficent computing, and it is distributed computing that brings intelligence closer to where decisions get made. Edge inference, local models, and hybrid architectures that can function when connectivity fails or becomes expensive. Move data in the most efficient way possible, wherever it needs to be.
Think like a designer of household utilities. A family chooses shorter showers, efficient bulbs, and thermostat schedules based on meter readings they can see and control. Software teams need the same visibility and control over their AI consumption: prompt length, context length, model size, reasoning depth, caching, and routing.
Building for Reality
The winners won't be whoever throws the most GPUs at the problem. The winners will be whoever makes infrastructure resilient and efficient enough to sustain growth without subsidies.
Price with the meter in mind. Share per-token assumptions with customers in plain language. Route to the smallest model that meets requirements. Expect supply friction as constant. Treat efficiency as a competitive advantage, not an afterthought.
Tokens can look cheap on paper. Compute and power cost real money and time. That mismatch creates fragile margins for products that push long context and deep reasoning on every request. Transparency around true costs strengthens trust and keeps companies alive when usage spikes.
The lesson runs simple and firm: AI compute spend will top a trillion dollars annually by the early 2030s, but the economics are broken. Training and inference costs are rising faster than efficiency gains. The gap is being papered over with subsidies from hyperscalers, but that's not sustainable.
This creates an opening. The next chapter of AI won't be written by whoever owns the most data centers. The next chapter will be written by whoever makes intelligence work everywhere—including the places where the cloud doesn't reach.