
The GPU King Is Hedging
NemoClaw, competitor chips, and everything about where Nvidia thinks this is going

Yesterday at GTC, Nvidia officially launched NemoClaw, the open-source agent platform it had been pitching to enterprise software companies for weeks. The platform runs on AMD, Intel, and Google chips. A company whose valuation rests on hardware lock-in is now shipping software with none.
OpenClaw is an AI agent you interact with through WhatsApp, Slack, Discord, or iMessage. You text it a task and it executes: booking flights, managing files, writing code, browsing the web, pulling data from connected services. It runs locally on your own hardware, works with any major model, and surpassed React’s GitHub star count in 60 days after going viral in late January. Created by Austrian developer Peter Steinberger as a weekend project, it became the fastest-growing open-source repository in history.
Nvidia can keep every customer and still watch margins fall. All it takes is for those customers to have somewhere else they could go.
Why Nvidia Would Give This Away
Nvidia’s data center business generates margins around 70%. Those margins exist because customers are locked into CUDA, Nvidia’s programming layer that sits between AI code and the chips that run it. CUDA itself is free, but two decades of libraries, tools, and optimization work mean that switching to a competitor’s hardware requires rewriting and retuning code that already works. Most companies don’t bother.
So why ship software that makes chips interchangeable? Because Nvidia sees the lock-in eroding, and if hardware becomes a commodity, the profits migrate to whoever owns the software layer above it. NemoClaw is a bet that orchestrating agents matters more than running them.
NemoClaw is a bet that orchestrating agents matters more than running them. That bet only makes sense if Nvidia believes the hardware moat is already leaking.
What NemoClaw Adds
OpenClaw’s architecture combines what researchers call the “lethal trifecta“: access to private data, the ability to communicate externally, and the ability to process untrusted content. Within three weeks of going viral, security teams found over 40,000 instances exposed on the public internet. A critical remote code execution vulnerability meant one malicious link could compromise an entire machine. Twenty percent of the skills in ClawHub, OpenClaw’s plugin marketplace, were found to deliver malware. Microsoft’s security team advised that OpenClaw is “not appropriate to run on a standard personal or enterprise workstation.”
Enterprises wanted the capability but couldn’t accept the risk.
NemoClaw wraps OpenClaw in enterprise controls. OpenShell sandboxes agent execution with least-privilege access, restricting file system scope and network connections through YAML configuration rules. A privacy router inspects outbound requests and blocks sensitive data from reaching cloud-hosted models. Nemotron, Nvidia’s family of open models, handles local inference for tasks that shouldn’t leave the premises. The stack installs with a single command and runs on any hardware.
That last part is the tell. NemoClaw doesn’t require Nvidia chips. It runs on AMD, Intel, or Google silicon.
Why The Lock-In Is Eroding
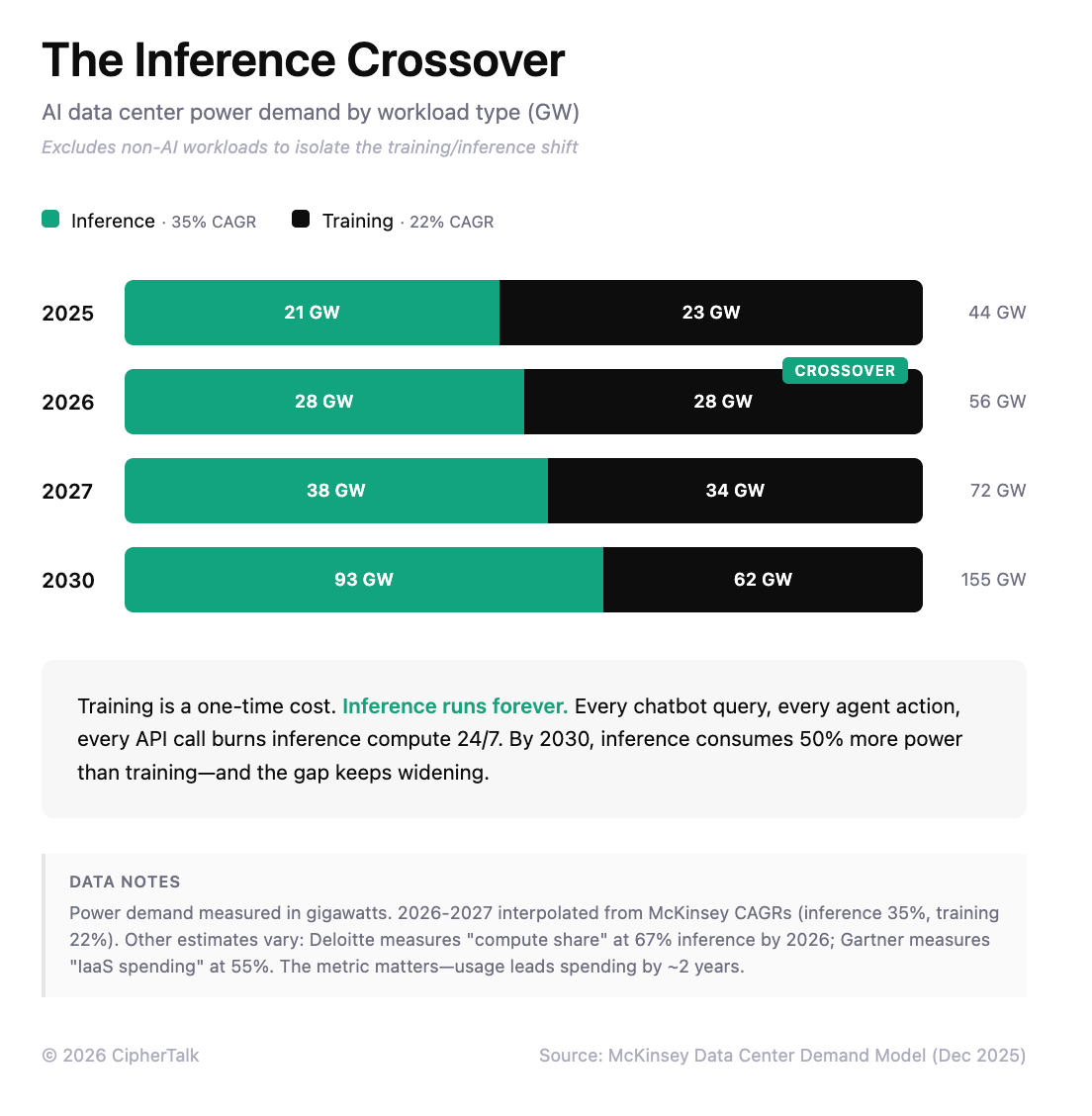
Training is where models learn from data; it happens once, requires massive compute bursts, and Nvidia’s GPUs remain unmatched. Inference is where trained models run continuously, handling billions of queries and generating revenue. Inference now consumes two-thirds of all AI compute, up from half in 2025 and a third in 2023. The shift matters because inference workloads are easier to optimize for specialized chips, and those chips are now reaching production scale.
Nvidia’s $20B acquisition of Groq in December was a bet on that shift. Groq’s chips were built specifically for inference, hitting 750 tokens per second where standard GPUs manage around 100. Nvidia bought the threat before it scaled.
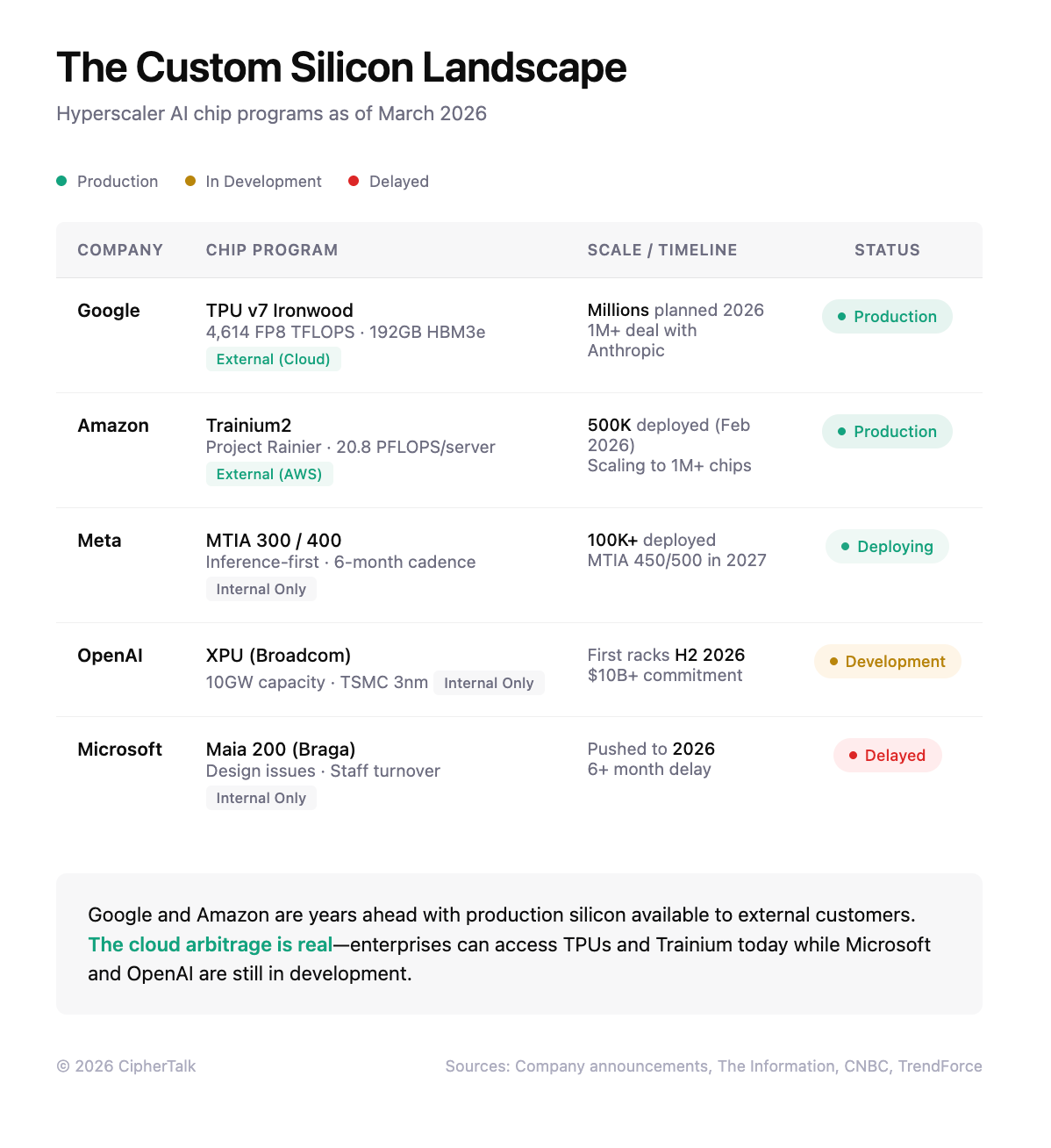
Meanwhile, the switching costs that protect CUDA are dropping. Google is building PyTorch compatibility for its TPU chips, which means developers can move code from Nvidia GPUs to Google TPUs without rewriting it. Anthropic has built infrastructure that runs Claude across Nvidia, Google, and Amazon chips simultaneously; their CPO told CNBC this multi-chip approach was the only way to meet demand. Google is now selling TPU access externally, with Anthropic’s deal for one million Ironwood chips representing the largest commitment to non-Nvidia AI hardware to date.
The Threat Is Margin Compression
Google and Amazon price their custom chips 30-40% below Nvidia for inference workloads. When Anthropic can credibly shift workloads between three vendors, the pricing conversation changes. Nvidia can keep every customer and still watch margins fall. All it takes is for those customers to have somewhere else they could go.
How fast will this play out? Slower than the narrative suggests, but faster than incumbents hope. Microsoft has spent billions on its Maia chip program and still delayed production to 2026. Google and Amazon succeeded because they started a decade ago. Internal AWS data from early 2024 showed Trainium handling just 0.5% of the AI workloads that Nvidia GPUs handled. Custom chips work well for predictable internal tasks like search or voice assistants. They don’t yet work for enterprise customers running unpredictable workloads at variable scale.
But the 2026-2027 window is when external TPU and Trainium sales grow large enough to appear as line items in earnings reports. The AI infrastructure market will grow from $242 billion to over $1.2T by 2030. Nvidia can lose ten points of share and still grow revenue. But 70% margins at 85% share is a different business than 55% margins at 75% share.
What GTC Tells Us
GTC runs through Thursday, and the technical announcements reinforce the pattern. Nvidia introduced “disaggregated inference,” splitting workloads between Rubin GPUs for prompt processing and Groq LPUs for token generation. The architecture exists because Nvidia now owns two chip lines optimized for different phases of inference, and combining them claims 35x higher throughput per megawatt. Three months ago, Groq was a competitor. Now it’s a component.
Huang announced $1 trillion in expected orders for Blackwell and Vera Rubin through 2027, double last year’s projection. He compared OpenClaw to Linux and Kubernetes: infrastructure every company will eventually need a strategy for. The demand story is intact. The margin story is the one worth watching.

What Breaks and What Ships
Gartner predicts 40% of agent AI projects will be abandoned by 2027. The failures will share a pattern: tight coupling between agent logic and specific hardware or cloud providers. The projects that ship will treat chips the way applications treat databases, as interchangeable backends behind a consistent interface. NemoClaw offers that interface. So do a growing number of startups building inference optimization and multi-cloud orchestration. The margin that used to live in silicon could migrate to whoever owns that layer.
That’s the signal from this week. Nvidia announced record demand and a hardware roadmap measured in trillions of dollars, but the strategic tell was a piece of open-source software designed to work on competitors’ chips. Hardware lock-in built the $4.4 trillion market cap. Software lock-in is the plan to protect it.
Excellent post, thank you.
Great insight . If nvidia solves the security problem of openclaw they will capture a huge market.